对工作集群的控制节点扩容¶
本文将以一个单控制节点的工作集群为例,介绍如何手动为工作集群的控制节点进行扩容,以实现自建工作集群的高可用。
Note
- 推荐在界面创建工作集群时即开启高可用模式,手动扩容工作集群的控制节点存在一定的操作风险,请谨慎操作。
- 当工作集群的首个控制节点故障或异常时,如果您想替换或重新接入首个控制节点, 请参考替换工作集群的首个控制节点
前提条件¶
- 已经通过 DCE 5.0 平台创建好一个工作集群,可参考文档创建工作集群。
- 工作集群的被纳管集群存在当前平台中,并且状态运行正常。
Note
被纳管集群:在界面创建集群时指定的用来管理当前集群,并为当前集群提供 kubernetes 版本升级、节点扩缩容、卸载、操作记录等能力的集群。
修改主机清单文件¶
-
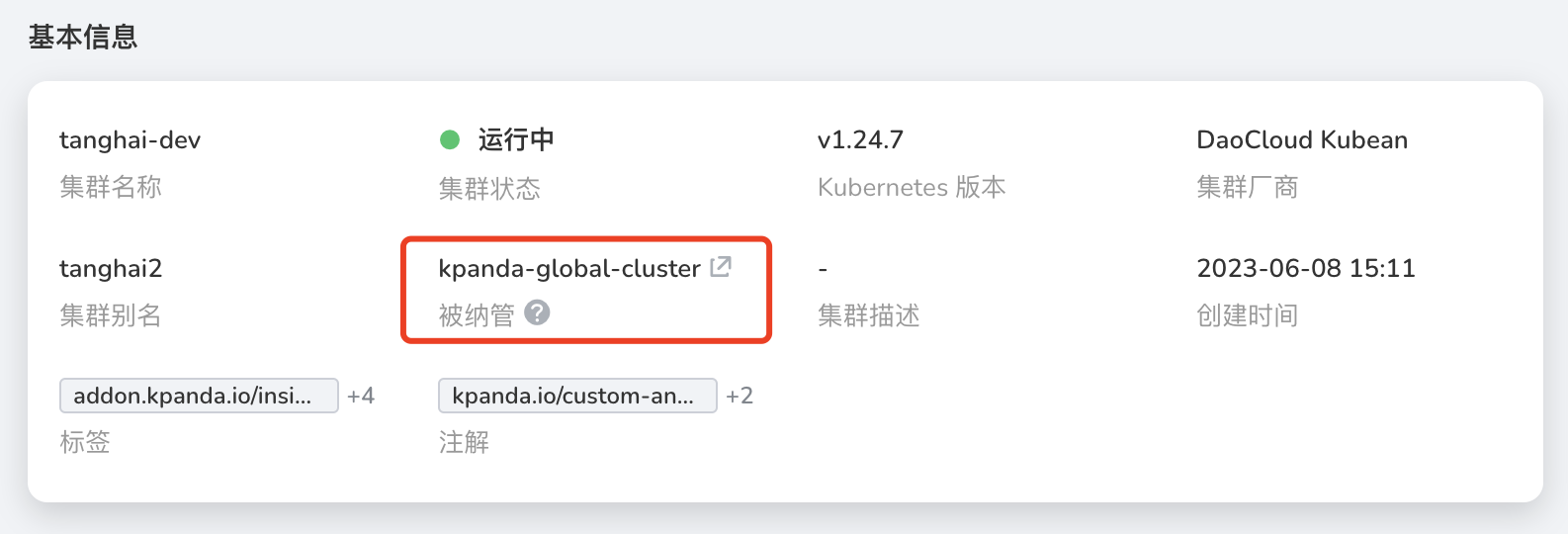
登录到容器管理平台,进入需要进行控制节点扩容的集群概览页面,在 基本信息 处,找到当前集群的 被纳管集群 , 点击被纳管集群的名称,进入被纳管集群的概览界面。
-
在被纳管集群的概览界面,点击 控制台,打开云终端控制台,并执行如下命令,找到待扩容工作集群的主机清单文件。
${ClusterName}:为待扩容工作集群的名称。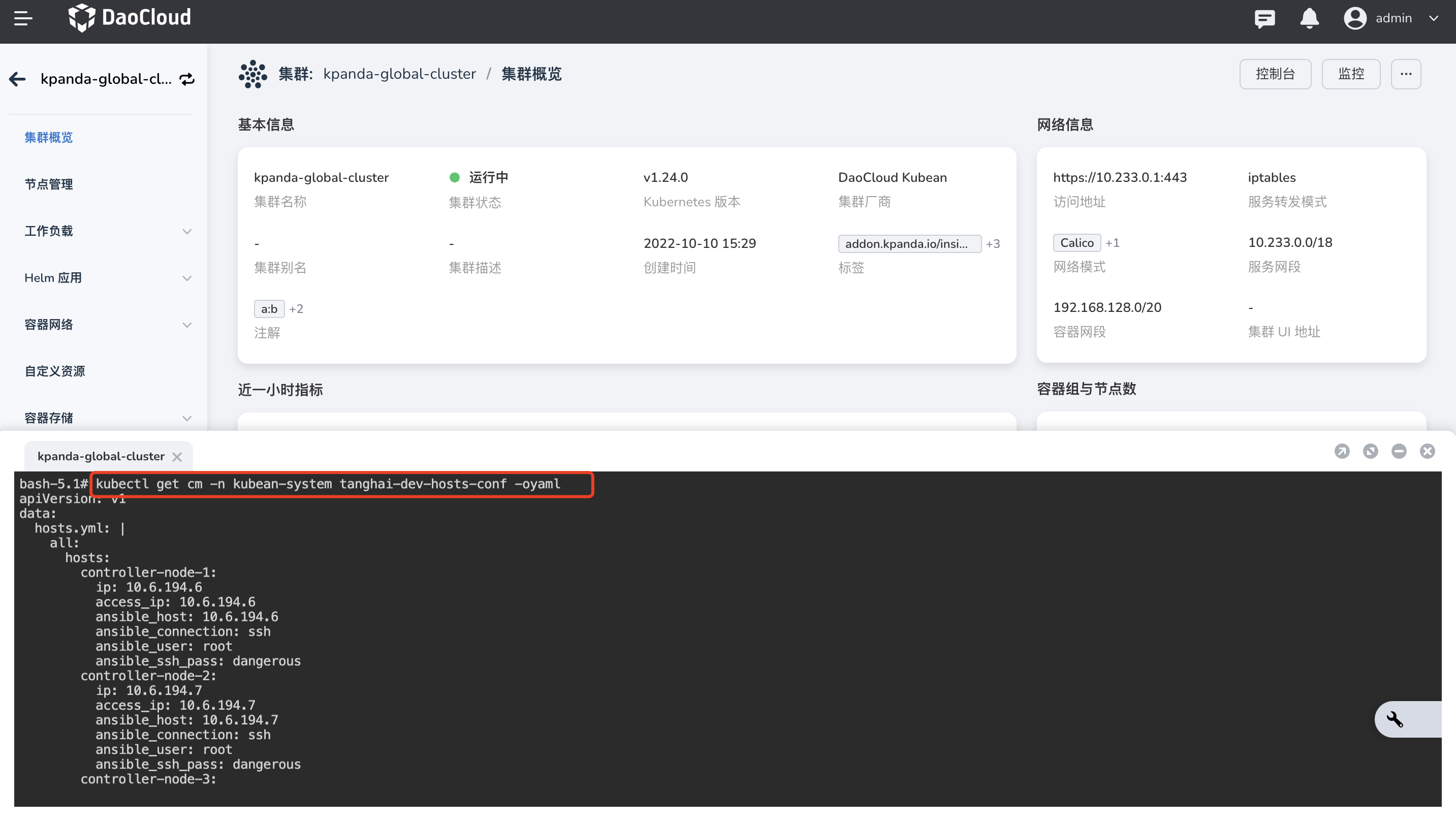
-
参考下方示例修改主机清单文件,新增控制节点信息。
apiVersion: v1 kind: ConfigMap metadata: name: tanghai-dev-hosts-conf namespace: kubean-system data: hosts.yml: | all: hosts: node1: ip: 10.6.175.10 access_ip: 10.6.175.10 ansible_host: 10.6.175.10 ansible_connection: ssh ansible_user: root ansible_password: password01 children: kube_control_plane: hosts: node1: kube_node: hosts: node1: etcd: hosts: node1: k8s_cluster: children: kube_control_plane: kube_node: calico_rr: hosts: {} ......apiVersion: v1 kind: ConfigMap metadata: name: tanghai-dev-hosts-conf namespace: kubean-system data: hosts.yml: | all: hosts: node1: # 原集群中已存在的主节点 ip: 10.6.175.10 access_ip: 10.6.175.10 ansible_host: 10.6.175.10 ansible_connection: ssh ansible_user: root ansible_password: password01 node2: # 集群扩容待新增的控制节点 ip: 10.6.175.20 access_ip: 10.6.175.20 ansible_host: 10.6.175.20 ansible_connection: ssh ansible_user: root ansible_password: password01 node3: # 集群扩容待新增的控制节点 ip: 10.6.175.30 access_ip: 10.6.175.30 ansible_host: 10.6.175.30 ansible_connection: ssh ansible_user: root ansible_password: password01 children: kube_control_plane: hosts: # 集群中的控制节点组 node1: node2: # 新增控制节点 node2 内容 node3: # 新增控制节点 node3 内容 kube_node: hosts: # 集群中的工作节点组 node1: node2: # 新增控制节点 node2 内容 node3: # 新增控制节点 node3 内容 etcd: hosts: # 集群中的 ETCD 节点组 node1: node2: # 新增控制节点 node2 内容 node3: # 新增控制节点 node3 内容 k8s_cluster: children: kube_control_plane: kube_node: calico_rr: hosts: {}
新增 ClusterOperation.yml 扩容任务¶
使用基于下面的 ClusterOperation.yml 模板,新增一个集群控制节点扩容任务 scale-master-node-ops.yaml 。
ClusterOperation.yml
apiVersion: kubean.io/v1alpha1
kind: ClusterOperation
metadata:
name: cluster1-online-install-ops
spec:
cluster: ${cluster-name} # (1)!
image: ghcr.m.daocloud.io/kubean-io/spray-job:v0.4.6 # (2)!
backoffLimit: 0
actionType: playbook
action: cluster.yml # (3)!
extraArgs: --limit=etcd,kube_control_plane -e ignore_assert_errors=yes
preHook:
- actionType: playbook
action: ping.yml
- actionType: playbook
action: disable-firewalld.yml
- actionType: playbook
action: enable-repo.yml # (4)!
extraArgs: | # 如果是离线环境,需要添加 enable-repo.yml,并且 extraArgs 参数填写相关 OS 的正确 repo_list
-e "{repo_list: ['http://172.30.41.0:9000/kubean/centos/\$releasever/os/\$basearch','http://172.30.41.0:9000/kubean/centos-iso/\$releasever/os/\$basearch']}"
postHook:
- actionType: playbook
action: upgrade-cluster.yml
extraArgs: --limit=etcd,kube_control_plane -e ignore_assert_errors=yes
- actionType: playbook
action: kubeconfig.yml
- actionType: playbook
action: cluster-info.yml
- 指定 cluster name
- 指定 kubean 任务运行的镜像,镜像地址要与之前执行部署时的 job 其内镜像保持一致
- 如果一次性添加 Master(etcd)节点超过(包含)三个,需在 cluster.yaml 追加额外参数
-e etcd_retries=10以增大 etcd node join 重试次数 - 离线环境下需要添加此 yaml,并且设置正确的 repo-list(安装操作系统软件包),以下参数值仅供参考
然后创建并部署 scale-master-node-ops.yaml。
执行完上述步骤,执行如下命令进行验证: